3 Návrh
Je realizovaný rôznymi modelmi systému na základe skôr definovaných požiadaviek. Počas návrhu sú vytvárané modely nielen na konceptuálnej a logickej úrovni, ale aj fyzický návrh ako príprava na implementáciu.
Cieľom kvalitného návrhu je, že databáza musí uchovávať údaje potrebné na plnenie informačných požiadaviek známych v čase návrhu databázy, ale aj budúcich požiadaviek. Údaje musia poskytovať platné a presné informácie, ktoré majú význam pre účel vyhotovenia. Takisto nemôžeme zabúdať, že databáza musí byť v budúcnosti do určitej miery rozšíriteľná [1].
Samotný návrh uskutočňujeme vtedy, keď sú nám známe finálne požiadavky, identifikované v predchádzajúcej fáze. Tie budú použité ako základ vývoja nového systému. Všeobecne nastáva prevod rámcového (všeobecného sémantického) porozumenia údajových štruktúr na ich technickú reprezentáciu (podľa ich technického chápania) [1].
Otázky typu: Aký/aká/aké? nahradíme otázkami typu: Ako?
Aké údaje sú požadované? → Ako budú údaje organizované?
Aké problémy sa budú riešiť? → Ako bude zaistený prístup k údajom? [1]
Táto fáza zahŕňa údajovú a funkčnú analýzu, keď sa v údajovej analýze vytvárajú modely na troch úrovniach štruktúry údajov a teda na troch úrovniach návrhu modelu DBS. Tým myslíme konceptuálnu, technologickú a implementačnú úroveň. Vytvorí sa konceptuálny model (napríklad E‑R diagram), potom sa tento model prevedie na technologický model (napríklad relačná schéma) a v konečnej fázy sa zvolí SRBD v závislosti od požiadaviek a komplexnosti štruktúry údajov [1].
3.1 Entitno‑relačný diagram (E‑R diagram)
Entitno‑relačný diagram (E‑R diagram) je grafický nástroj, ktorý sa používa pri návrhu databázových systémov na vyjadrenie modelu údajov, pričom charakterizuje pohľad na statickú časť systému. V rámci E‑R diagramu sú definované jednotlivé údajové objekty sveta (entity) a vzájomné vzťahy medzi nimi (relácie). E‑R diagramy pozostávajú z nasledujúcich prvkov:
- Entita je špecifickým predmetom záujmu z oblasti reálneho sveta. Je to akýkoľvek údajový objekt, ktorý je predmetom záujmu, o ktorom chceme uchovávať údaje.
- Atribút je elementárny prvok, ktorý vyjadruje bližšiu charakteristiku, vlastnosť alebo informáciu o konkrétnej entite. Identifikátorom alebo kľúčovým atribútom budeme nazývať atribút alebo množinu atribútov, ktorých hodnoty umožňujú jednoznačne rozlíšiť jednotlivé inštancie (záznamy) entity navzájom medzi sebou. Takýto atribút budeme nazývať primárnym kľúčom.
- Doména atribútu je obor hodnôt, ktorý môže atribút nadobúdať.
- Relácia (vzťah) je určitá forma väzby, spojenia medzi jednotlivými entitami, ktorú evidujeme. Medzi entitami môže existovať viac rôznych typov vzťahov [8].
Postup pri tvorbe E‑R diagramu
- Definícia entít.
- Pridelenie atribútov jednotlivým entitám.
- Definícia relácií (vzťahov) medzi entitami.
- Definícia kardinality relácií.
- Reprezentácia navrhnutej údajovej štruktúry s pomocou grafických notácií [8].
Po konceptuálnom návrhu databázy (vytvorenie E‑R modelu) nasleduje logický návrh databázy.
3.2 Údajový model databázy
Po tom ako sme vytvorili E‑R diagram, je potrebné určiť spôsob reprezentácie tohto diagramu v báze údajov. Organizáciu údajov navrhujeme s pomocou údajového modelu.
Údajový model:
- Je množina pravidiel, podľa ktorých sú organizované logické vzťahy medzi údajmi.
- Zobrazuje štruktúru údajov na úrovni ich typov.
- Je prostriedok, s pomocou ktorého sú údaje organizované na logickej úrovni.
- Pozostáva z pomenovaných logických jednotiek údajov a vyjadruje vzťahy medzi údajmi.
- Poznáme niekoľko údajových modelov. Rozdiel medzi nimi spočíva v spôsobe reprezentácie vzťahov medzi údajmi [8].
Typy údajových modelov
Poznáme tri základné údajové modely založené na záznamoch: hierarchický údajový model, sieťový údajový model a relačný údajový model.
3.2.1 Hierarchický údajový model
Je špeciálnym prípadom sieťového modelu, na ktorom boli postavené prvé databázové systémy. Tento model je založený na hierarchickej (stromovej) štruktúre údajov vychádzajúcej z koreňa, pri ktorej sa využíva vzťah nadradenosti a podradenosti (rodič a potomok) na opis vzájomných vzťahov. Údajovým štruktúram na jednotlivých úrovniach sa hovorí uzly. Keď z uzla nevychádza ďalšia vetva, nazývame ho list. Aj keď tento model často vhodne vystihuje hierarchiu vzťahov v realite (napríklad štát → kraj → okres → obec) a v minulosti si našiel v praxi široké uplatnenie, v súčasnosti sa v databázových systémoch využíva len zriedkavo.
Hierarchický model sa priamo neopiera o matematickú teóriu, avšak čiastočne používa terminológiu teórie grafov (graf, uzol, hrana). Napríklad záznam zodpovedá uzlu v grafe [14].
Pre hierarchickú štruktúru platí, že:
- Každý potomok má len jedného rodiča.
- Existuje jediný rodič, ktorý nie je potomok (označujeme ho aj ako koreň stromovej štruktúry).
- Potomok v jednom vzťahu môže byť rodičom v inom [11].
Hierarchické modelovanie zodpovedá vzťahom typu 1 : N a 1 : 1. Základnou výhodou hierarchického systému je rýchle vyhľadávanie entít, ktoré sú podriadené určitej entite. Naopak vyhľadávanie entity, ktorá je nadriadená znamená sekvenčné prehľadávanie celého stromu (v súčasnosti neefektívne). Pri vyhľadávaní údajov sa postupuje vždy od koreňového uzla (záznamu) cez stromovú štruktúru k požadovanému uzlu, pričom ku každému záznamu existuje len jediná cesta [8].
Nevýhody hierarchického modelu:
- Neumožňuje modelovanie väzieb M : N.
- Zložité vkladanie nových uzlov (záznamov) a takisto zložité mazanie existujúcich uzlov. To znamená, že vzťahy medzi údajmi sú zabudované priamo v štruktúre databázy a je veľmi problematické ich v prípade potreby neskôr meniť.
- Neprirodzená organizácia údajov.
- Tvorba dopytov je závislá od logickej štruktúry databázy [8].
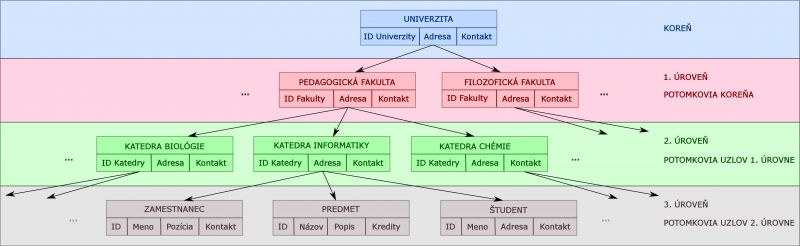
Obrázok 3. Hierarchický údajový model [8].
3.2.2 Sieťový údajový model
Sieťový model vznikol približne v rovnakom časovom období ako hierarchický model. Využíva sieťovú štruktúru údajov, v ktorej (na rozdiel od hierarchického modelu) môže byť každý prvok v sieti zviazaný s ktorýmkoľvek iným prvkom (každý prvok môže mať aj viac rodičov) [12].
Tvoríme ho s pomocou orientovaného grafu, v ktorom sú entity zobrazené s pomocou uzlov a vzťahy s pomocou odkazov (prepojovacích čiar). Tento model teda údaje predstavuje ako množinu záznamov (entít) a párových vzťahov medzi nimi, ktoré môžu mať vzťahy typu 1 : 1, 1 : N alebo M : N [15].
Tým rozširuje možnosti hierarchického modelu a umožňuje vernejšiu reprezentáciu vzťahov, avšak na úkor jednoduchosti modelu.
Atribúty záznamov v sieťových modeloch môžu byť jednoduché, opakujúce sa, zložené alebo zložené opakujúce sa. Na rozdiel od predchádzajúceho hierarchického údajového modelu, sieťový model môže obsahovať aj cykly a slučky [15].
Sieťový graf má odstrániť hlavné nevýhody hierarchického modelu. Model zaručuje minimálnu redundanciu (výskyt rovnakých údajov), pretože každá entita sa nachádza v báze údajov iba raz. Keď sa nachádza táto entita vo viacerých vzťahoch, vedie k nej viac odkazov v rôznych vzťahových súboroch. Z toho vyplýva aj základná nevýhoda sieťových modelov, ktorou je veľmi náročná modifikovateľnosť. Napríklad so zmenou počtu entít (najmä pri odstraňovaní entít) je potrebné prechádzať všetky vzťahové súbory a opravovať (rušiť) odkazy. Sieťový model bol z dôvodu svojej implementačnej náročnosti a zložitosti používaný pomerne málo [13].
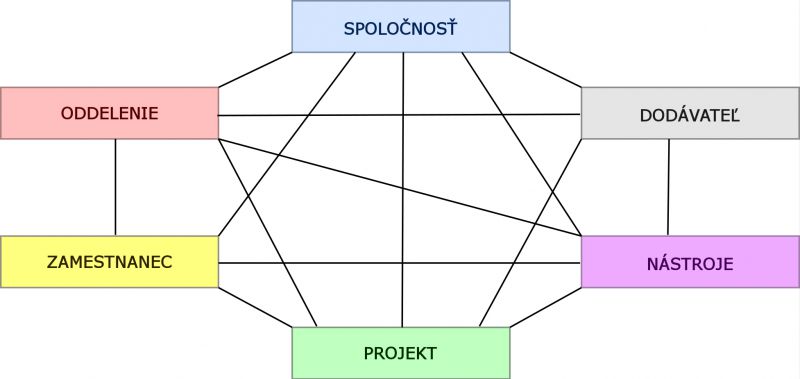
Obrázok 4. Sieťový údajový model.
3.2.3 Relačný údajový model (RDM)
Relačný údajový model vychádza z teórie množín. Vznikol v roku 1970, kedy ho prvý raz publikoval Dr. E. F. Codd. Väčšina dnešných databázových systémov je založená práve na relačnom údajovom modeli. Ide o logické vyjadrenie väzieb medzi jednotlivými údajmi. Manipulácia s údajmi je založená na operáciách relačnej algebry. Tieto operácie zahŕňajú množinové operácie ako zjednotenie, prienik, rozdiel a karteziánsky súčin. Medzi špeciálne relačné operácie patria selekcia, spojenie, delenie a projekcia [10].
Medzi základné pojmy relačného údajového modelu patrí:
- Relácie – sú základnými prvkami relačného údajového modelu. V implementácii databázového systému sú relácie reprezentované ako dvojrozmerné tabuľky. Každá tabuľka potom zastupuje konkrétnu entitu reálneho sveta. Relácia sa skladá z atribútov a z usporiadaných n‑tíc.
- Atribúty – sú reprezentované jednotlivými stĺpcami tabuliek a vyjadrujú konkrétne vlastnosti o entitách. Hodnota atribútu je vyjadrená konkrétnym údajom v danej bunke tabuľky.
- Primárny kľúč (PK) – jednoznačný identifikátor v tabuľke, ktorý je reprezentovaný jedným alebo viacerými stĺpcami tabuľky.
- N‑tica – zodpovedá jednému riadku tabuľky.
- Doména – vyjadruje množinu dovolených hodnôt, ktoré sa v konkrétnom stĺpci môžu vyskytovať. Ide o skalárne hodnoty rovnakého údajového typu. Skalár je hodnota, ktorá reprezentuje najmenšiu sémantickú jednotku údajov. Napríklad pre atribút „Meno študenta“ je údaj „Peter“ skalárna hodnota. Domény zohrávajú v relačnom modeli veľmi dôležitú úlohu, pretože sú základnými nositeľmi informácie [8].
Tabuľka 1. Analógia pojmov: relačný údajový model – systémy súborov [10].
| Relačný pojem | Reprezentácia | Súborová analógia |
|---|---|---|
| Relácia | Tabuľka | Súbor |
| N‑tica | Riadok | Záznam |
| Atribút | Stĺpec | Položka |
| Hodnota atribútu | Hodnota bunky | Hodnota položky |
Základné vlastnosti každej relácie (tabuľky):
- Neobsahuje duplicitné n‑tice – táto vlastnosť vychádza z faktu, že telo relácie je matematická množina (množina n‑tíc), a podľa definície neobsahuje duplicitné prvky. Základným predpokladom na splnenie tohto bodu je nevyhnutná existencia primárneho kľúča v každej relácii.
- N‑tice sú neusporiadané (zhora nadol) – n‑tice tvoria matematickú množinu (nie je usporiadaná) hoci z praktického hľadiska je často vhodné udržiavať reláciu ako usporiadanú množinu. Na druhej strane neusporiadanosť umožňuje zjednodušiť algoritmy na prácu s reláciou.
- Atribúty sú neusporiadané (zľava doprava) – atribúty takisto tvoria matematickú množinu (nie je usporiadaná). Táto vlastnosť hovorí o tom, že k jednotlivým stĺpcom alebo k hodnotám atribútu pristupuje prostredníctvom identifikátora (mena atribútu) a nie podľa pozície v riadku. To umožní tvorbu aplikácií nezávislých od údajov.
- Hodnoty atribútov sú atomické – to znamená, že každému atribútu je priradená vždy len jedna hodnota a nie množina hodnôt. Je potrebné, aby všetky atribúty boli atomické, čím dosiahneme to, že v relácii sa nemôžu vyskytovať tzv. opakujúce sa skupiny atribútov, ktoré sa vyskytujú v nenormalizovaných záznamoch. Relácii bez opakujúcich sa skupín hovoríme, že je normalizovaná [8].
Obrázok 5. Príklad relácie (tabuľky s M riadkami a N stĺpcami) [8].
Relačný údajový model podľa pôvodnej definície vychádzal z nasledujúcich požiadaviek:
- Zabezpečiť vysoký stupeň údajovej nezávislosti.
- Zabezpečiť minimálnu redundanciu údajov spolu s konzistenciou údajov s podporou sémantiky jazyka.
- Sprístupniť databázu s pomocou množinovo orientovaného neprocedurálneho jazyka.
- Umožniť jednoduchým spôsobom reštrukturalizáciu a rast údajového modelu [9].
Obrázok 6. Relačný údajový model [8].
Relačný údajový model je najčastejšie používaný model v dnešných databázových systémoch. Tento model však obmedzuje štruktúru a vzťahy uchovávaných údajov na množinu tabuliek nad preddefinovanou množinou základných údajových typov. Významnou výhodou tohto modelu je jednoduchosť a v dôsledku toho aj jednoduchá štandardizácia a prenositeľnosť. Nevýhodou však je rozdielnosť reálnych údajov od vnútorného tabuľkového modelu databázy. Vzťahy medzi údajmi je možné reprezentovať iba tabuľkami, čo v aplikáciách s komplikovanejším údajovým modelom vedie k množstvu tabuliek vzájomne previazaných s pomocou kľúčov [22].
Dochádza tým k strate prehľadnosti, databáza sa stáva horšie spravovateľnou a budúce zmeny v údajovom modeli aplikácie nútia programátorov k citeľným zásahom do jeho tabuľkovej reprezentácie. Rad aplikácií, napríklad z oblasti dizajnu, multimédií, geografických systémov a podobne, však potrebuje taký údajový model, ktorý umožní lepšiu korešpondenciu medzi zložitými reálnymi údajmi a ich reprezentáciou v databázovom systéme. Týmto modelom je objektový údajový model [22].
Okrem vyššie uvedených údajových modelov, s ktorými sa môžeme stretnúť v súvislosti s DBS v súčasnosti poznáme aj: objektovo orientovaný model a objektovo‑relačný model.
3.2.4 Objektový údajový model
Objektový údajový model v DBS vychádza zo známych princípov objektovo orientovaného modelovania a programovania. Je však ďalej obohatený o techniky reprezentácie vzťahov, dopytovania, transakčného prístupu a podobne [22].
3.2.4.1 Dôvody použitia objektových údajových modelov
Pri nových databázových aplikáciách dáva väčšina vývojárov prednosť objektovej technológii, pretože vývoj zložitých aplikácií je omnoho rýchlejší a neskoršie úpravy sú jednoduchšie. Objektová technológia poskytuje niekoľko výhod, akými sú napríklad:
- Objekty podporujú bohatšie údajové štruktúry, ktoré omnoho prirodzenejšie opisujú skutočné údaje.
- Programovanie je jednoduchšie. Je ľahšie sledovať, čo práve robíte a s čím práve pracujete.
- Pojatie objektu ako „čiernej skrinky“ so zapuzdrenými prostriedkami umožňuje programátorom zdokonaľovať vnútorné operácie v objekte, bez toho, aby boli ovplyvňované ostatné časti aplikácie.
- Vďaka objektom je možné jednoduchým spôsobom prepojovať rôzne technológie a aplikácie.
- Objektová technológia je použitá v mnohých nových nástrojoch.
- Objekty zaisťujú oddelenie používateľského rozhrania od zvyšku aplikácie. Keď treba prijať novú technológiu používateľského rozhrania (možno nejakú doposiaľ neznámu technológiu budúcnosti), tak bude možné opätovne použiť väčšinu kódu [22].
3.2.4.2 Objektovo orientované systémy (object database management system – ODBMS)
ODBMS priniesli oproti relačným databázam kvalitnejšie údajové a procedurálne modelovanie. Prejavuje sa predovšetkým nasledujúcimi charakteristikami:
- Spájanie príbuzných údajov – ODBMS umožňujú prirodzenejšiu reprezentáciu zložitejších údajových štruktúr. Údaje, ktoré navzájom súvisia v realite sa spolu uchovávajú aj v externých pamätiach.
- Spájanie údajov s funkciami – ODBMS poskytujú tradičné objektovo orientované črty ako: spájanie údajov s funkciami, ukrývanie údajov, používateľsky definovateľné typy, typové dedenie, polymorfizmus a podobne.
- Spájanie databázového a programovacieho jazyka – ODBMS, na rozdiel od SQL relačných DBMS, ponúkajú výpočtovo úplný jazyk. Snažia sa tiež integrovať databázové prostredie s programovacím prostredím [17].
Základné pojmy objektovo orientovaného modelu:
- Objekty – objektovo orientovaný model je založený na dekompozícii informácií z reálneho sveta na tzv. objekty. Pod pojmom objekt sa rozumie každá (aj štruktúrovaná) entita, ktorá je jednoznačne a nezávisle identifikovaná v rámci určitého kontextu okolitého sveta. Objekt tak má jednoznačnú identitu a potom platí, že každé dva objekty sú vzájomne odlíšiteľné. Identita objektu je určená identifikátorom OID, ktorý je generovaný systémom. OID je unikátny, nemenný počas celej doby existencie objektu a skrytý pre programátora i koncového používateľa [21].
- Triedy – objekty sú charakterizované pomocou tried. Trieda je abstraktný opis objektu, určuje údajové zložky objektu a operácie (nazývané metódy), ktoré sa dajú nad objektom realizovať. Každý objekt je inštanciou nejakej triedy. Všeobecne je možné inštanciovať neobmedzený počet objektov jednej triedy, ktoré sú štrukturálne zhodné.
- Literály – literál je údajová entita určitého údajového typu, ktorá však na rozdiel od objektov nemá vlastnú identitu. Literály sa obvykle vyskytujú ako údajové atribúty objektov. Množina operácií nad údajovým typom literálov je pevne stanovená a nie je možné ju meniť [21].
- Zapuzdrenie – okolie objektov má prístup iba k rozhraniu operácií. Vlastná implementácia operácií je vždy pred okolím skrytá. Ide o typickú vlastnosť objektovo orientovaného prístupu, ktorá zvyšuje mieru abstrakcie a nezávislosti objektov [22].
Okrem skrývania implementácie je možné skrývať aj časti rozhraní. Atribúty a operácie sa dajú označiť za verejné (public) alebo súkromné (private). Niektoré systémy zavádzajú ešte jednu úroveň, obvykle nazývanú chránené (protected). Takto označené atribúty a operácie sú prístupné v objektoch definovanej triedy a v objektoch tried odvodených od tejto triedy [21]. - Dedičnosť – dedičnosť je ďalšou typickou vlastnosťou objektového modelu. Vychádza z myšlienky, že niektoré triedy môžu byť špecializovanou verziou inej triedy, respektíve určitá trieda je zovšeobecnením jednej alebo viacerých špeciálnejších tried. Ak je trieda odvodená od inej triedy, dedí všetky jej atribúty a operácie. Ďalej môže doplniť nové atribúty a operácie, prípadne predefinovať zdedené operácie [21].
- Polymorfizmus – polymorfnými operáciami sa označujú operácie, ktoré sa dajú realizovať nad objektami rôznych tried. Činnosť operácie sa pritom môže líšiť podľa triedy objektu, nad ktorým je realizovaná. V objektovo orientovaných programovacích jazykoch sa polymorfizmus metód obvykle obmedzuje na triedy, ktoré sú vo vzťahu generalizácia/špecializácia [22].
Údajový model ODBMS:
- Objektovo orientované systémy využívajú údajový model, ktorý má objektovo orientované aspekty ako sú triedy s atribútmi a metódami a integritnými obmedzeniami.
- Poskytujú objektové identifikátory (OID) pre každú trvalú inštanciu triedy.
- Podporujú: zapuzdrenie, násobnú dedičnosť, abstraktné údajové typy.
- Kombinujú prvky objektovo orientovaného programovania s databázami.
- Rozširujú funkčnosť objektových programovacích jazykov (C++, Smalltalk, Java).
- Poskytujú úplnú schopnosť programovania databázy.
- Údajový model aplikácie a údajový model databázy sa vo výsledku takmer zhodujú.
- Výsledný kód sa dá efektívnejšie udržovať [17].
V porovnaní s relačnými systémami sa však znížila jednoduchosť a matematická precíznosť.
3.2.4.3 Objektovo‑relačné systémy (ORSRBD)
ORSRBD sa snažia využiť dobré vlastnosti z relačných aj z objektových systémov. Je tu zachovaná jednoduchosť z relačného modelu a navyše získavajú výhody z objektového modelu.
Údajový model ORSRBD:
- ORSRBD využívajú údajový model tak, že „pridávajú objektovosť do tabuliek.“
- Všetky trvalé údaje sú v tabuľkách, ale niektoré položky môžu mať bohatšiu údajovú štruktúru, nazývanú abstraktné údajové typy (ADT).
- ADT je údajový typ, ktorý vznikne skombinovaním základných údajových typov.
- Podpora ADT je atraktívna, pretože operácie a funkcie asociované s novými údajovými typmi môžu byť použité k indexovaniu, ukladaniu a získavaniu záznamov na základe obsahu nového údajového typu.
- ORSRBD sú nadmnožinou RSRBD. Ak nevyužijeme žiadne objektové rozšírenie sú ekvivalentné SQL2.
- Preto majú obmedzenú podporu dedičnosti, polymorfizmu, referencií a integrácie s programovacím jazykom [17].
3.2.5 Porovnanie relačných DBS, ODBMS a ORSRBD
Ako sme už spomínali, v súčasnosti sa najviac využívajú práve tieto tri typy DBS. Keď si vývojár vyberá, aký typ DBS použije, mal by podrobne poznať všetky výhody a nevýhody týchto troch modelov. Medzi najhlavnejšie patria:
- Relačné systémy sú dobré na riadenie veľkého množstva údajov.
- OO programovacie jazyky sú dobré vo vyjadrovaní zložitých vzťahov medzi objektami.
- RSRBD sú dobré na vyhľadávanie údajov, ale poskytujú malú podporu na manipuláciu s nimi.
- OO programovacie jazyky sú výborné na manipuláciu s údajmi, ale poskytujú malú alebo žiadnu podporu pre nemennosť a vyhľadávanie údajov.
- Tieto prístupy sú protichodné a preto je ich skĺbenie trochu komplikované.
- OO model poskytuje základné vlastnosti objektov – zapuzdrenie, dedičnosť a polymorfizmus. Naviac každý objekt má jednoznačnú identifikáciu, ktorá umožňuje používanie odkazov.
- RSRBD poskytujú vlastnosti, ktoré OO programovacie jazyky nemajú, ako napríklad rýchle vyhľadávanie, zdieľanie objektov, prepracovaný systém opráv chýb pre databázové operácie, trvalé uloženie, atď. [17].
Pri návrhu databázy nemôžeme zabudnúť na normalizáciu údajov, čo je požadovaný krok k správnemu návrhu databázy. Tento proces pomáha zabrániť nadbytočnosti údajov a zlepšuje ich integritu.
3.3 Normalizácia
Normalizácia relačnej databázovej schémy je postupný proces, v rámci ktorého sa pôvodné relácie nahrádzajú novými s jednoduchšou štruktúrou. Normalizácia databázovej schémy predstavuje úpravu vzájomných vzťahov v databáze. Na začiatku návrhu je štruktúra relácií nenormalizovaná, to znamená taká, ako si ju predstavuje používateľ. Externé predstavy používateľa o obsahu databázy je nevyhnutné upraviť do stavu použiteľného v relačnom systéme, čo je práve súčasť normalizácie. Proces normalizácie znamená postupné rozloženie pôvodných „nenormalizovaných“ tabuliek do sústavy viacerých menších tabuliek tak, aby sa údaje obsiahnuté v pôvodných tabuľkách nestratili [17].
Výsledkom normalizácie je rozumné rozloženie atribútov do tabuliek. Žiadanou vlastnosťou databázy, ktorú možno dostať s pomocou normalizácie je, že všetky atribúty medzi ktorými je funkčná závislosť, sú v jednej relačnej tabuľke. Normalizáciu možno charakterizovať ako proces, ktorý je možné použiť v ľubovoľnom okamihu pri navrhovaní databázy. Výhodou databázy ktorá obsahuje normalizované relačné tabuľky, sú hlavne jednoduchší prístup používateľov k údajom v databáze, lepšie udržiavanie údajov a nižšie pamäťové nároky [15].
Príklad nežiadanej duplicity údajov:
Predstavme si tabuľku „Spoločnosť“ s atribútmi: názov spoločnosti, adresa spoločnosti, kontakt, výrobok. Táto spoločnosť by dodávala tisíc rôznych výrobkov. Z toho vyplýva, že tabuľka by obsahovala tisíckrát (tisíc inštancií) rovnaký údaj o názve spoločnosti, rovnakú adresu, rovnaký kontakt na spoločnosť, ale každá z týchto tisícich inštancií (každý riadok tabuľky) by obsahovala inú hodnotu v atribúte „Výrobok.“ Toto, samozrejme, nechceme. Okrem zvýšenej náročnosti na úložisko pamäte databázy, nám vznikajú takisto aj problémy s anomáliami.
Úprava databázy do príslušnej normálnej formy umožňuje eliminovať jej anomálie. Odstránenie anomálií v databáze zabezpečí jej konzistentnosť, efektívnosť vyhľadávania, a tiež minimalizáciu redundancie údajov [17].
Medzi základné anomálie databázy patria:
- Anomália vkladania nových údajov – situácia, keď do (logickej) relácie nie je možné vložiť nový záznam z dôvodu umelej závislosti od inej relácie.
Uvedieme na príklade povinného členstva, keď má entita „Študent“ povinné členstvo v relácii s entitou „Študijná skupina.“ To znamená, že každý študent musí byť povinne zaradený do konkrétnej študijnej skupiny. Ak potrebujeme vložiť do databázy údaje o novom študentovi, nemôžeme to vykonať až do chvíle, kým nie je vytvorená študijná skupina, do ktorej ho priradíme. - Anomália aktualizácie údajov – ak pri aktualizácii jednej údajovej hodnoty je nevyhnutné súčasne aktualizovať niekoľko údajových záznamov.
Uvažujeme o situácii, keby v školskom systéme neexistovala entita „Predmet,“ v ktorej uchovávame informácie o všetkých predmetoch. Jednotlivé predmety by sme vkladali do tabuľky „Študent,“ kde by sme vytvorili atribúty: Predmet 1, Predmet 2 … Predmet N.
Teraz si predstavme situáciu, keby sme chceli aktualizovať názov predmetu „databázové systémy 1“ napríklad na názov: „tvorba databázových systémov.“ V tomto príklade by sme museli každému študentovi v systéme prepísať tento nový názov predmetu, čo je samozrejme veľmi nepraktické, zdĺhavé a najmä vedúce k vzniku chybných údajov.
V situácii keď máme vytvorené entity „Študent“ aj „Predmet,“ tento nový názov predmetu aktualizujeme iba v entite (tabuľke) „Predmet,“ v ktorej sa informácie o predmete „databázové systémy 1“ nachádzajú iba raz. Tento spôsob nám uľahčí prácu a nevedie k tvorbe chybných údajov v databáze.
- Anomália odstraňovania údajov – ak odstránenie údajov spôsobí nežiadúcu a nenávratnú stratu aj iných dôležitých údajov.
Uvažujeme o príklade keď máme tabuľku „Dodávateľ,“ ktorá má atribúty: ID dodávateľa, Názov dodávateľa, Adresa dodávateľa, Kontakt dodávateľa, Výrobok. V databáze by sa nachádzal konkrétny dodávateľ, ktorý by do našej spoločnosti dodával nejaké výrobky. Naša spoločnosť by sa rozhodla, že výrobky od tohto dodávateľa ďalej nebude potrebovať. Preto by sme z databázy vymazali všetky výrobky, ktoré nám tento dodávateľ dodáva. S týmito výrobkami by sme ale vymazali aj údaje o: názve tohto dodávateľa, adresu a kontakt na tohto dodávateľa. V našej databáze by sa teda viacej tento dodávateľ nenachádzal. Predstavme si situáciu, že by sme sa po nejakom čase rozhodli znova osloviť tohto dodávateľa so žiadosťou o spoluprácu. V databáze už ale nemáme žiadny údaj o tejto spoločnosti, pretože o tieto údaje sme prišli pri mazaní výrobkov, ktoré tento dodávateľ dodával.
Riešením je dekompozícia tejto tabuľky do dvoch tabuliek:
- Dodávateľ – tu by sa nachádzali údaje o spoločnostiach, ktoré nám dodávajú výrobky.
- Výrobok – tu by sa nachádzali údaje o jednotlivých výrobkoch.
Existuje niekoľko spôsobov, ktoré vedú k lepšiemu návrhu:
- Nepotrebné údaje by mali byť v oddelených tabuľkách.
- Údaje, ktoré je možné vypočítať, nie je nevyhnutné ukladať (napríklad máme čísla A a B, ktoré sú uložené a zaujíma nás ich súčin A × B, potom tento súčin nie je potrebné ukladať).
- Návrh musí odpovedať všetkým podmienkam, ktoré boli definované pri analýze. Je jednoduché pri návrhu si nevšimnúť nejakú podmienku. Používateľ ľahko objaví pri konzultácii v E‑R diagrame chybnú podmienku, ale nie vždy objaví nejakú chýbajúcu.
- Pri voľbe atribútov je dôležité dbať na ich jasné názvy. Je vhodné sa vyhýbať aj rovnakým názvom pre odlišné pole, napríklad pole primárneho kľúča nazvané ID je vhodné doplniť o konkrétny predmet tabuľky (ID zamestnanca, ID zákazníka…).
- Nie je vhodné vytvárať príliš veľa vzťahov – napríklad študent patrí do nejakej študijnej skupiny, tá patrí k nejakej katedre a tá je priradená na určitú fakultu. Naopak je potrebné pokryť vzťahy tak, aby bolo možné dohľadať všetky spojitosti.
- Je nevyhnutné rozdeliť vzťahy kardinality M : N na dva vzťahy 1 : N a N : 1 s pomocou fiktívnej novovytvorenej tabuľky práve k tomuto vzťahu.
- Je vhodné zamyslieť sa nad obmedzením a teda nad tvorbou limitov, ktoré vyplývajú z použitia aplikácie, napríklad keď vek študenta na strednej škole nemôže presiahnuť 25 rokov, že pohlavie je len mužské alebo ženské alebo, že e‑mailová adresa musí obsahovať zavináč. Zabránime tým neskorším problémom pri implementácii.
- Nie je vhodné ukladať príliš veľa údajov, ktoré nesúvisia s cieľom a účelom aplikácie, pretože to môže v konečnom dôsledku viesť k obťažovaniu používateľa aj osoby, ktorá údaje poskytuje. Napríklad zhromažďovaním informácií o osobách s cieľom registrácie na odber elektronických správ, potom nie je dôležité poznať a ukladať farbu očí alebo obľúbené jedlo (ak nejde o informačný portál určený na varenie). Je vhodné zvážiť aj náročnosť a čas potrebný na spracovanie všetkých takých údajov a to aj v závislosti od následnej rýchlosti databázy.
- Je potrebné dodržať prvé tri normálové formy tak, že v každom poli (atribútu) sú uložené iba atomické hodnoty, z ktorých tie nekľúčové budú vždy úplne závislé od celého primárneho kľúča a v najlepšom prípade nebudú vznikať tranzitívne závislosti.
- Na tvorbu primárneho kľúča je vhodné vytvoriť nové pole, ako ho vytvárať z kombinácie existujúcich polí. Nie vždy bude platiť, že táto kombinácia musí byť jedinečná počas celého obdobia životnosti databázy.
- Pri zaisťovaní referenčnej integrity je potrebné dbať na to, aby cudzí kľúč nemal vzťah k primárnemu kľúču z inej tabuľky, ktorá už neexistuje.
- Je vhodné mať na pamäti dostatočné zabezpečenie databázy a obmedzenie prístupových práv pre jednotlivých používateľov. Nie je možné sprístupniť prehliadanie údajov nepovolaným používateľom aj v prípadoch, keď ich nemôžu zmeniť [1].
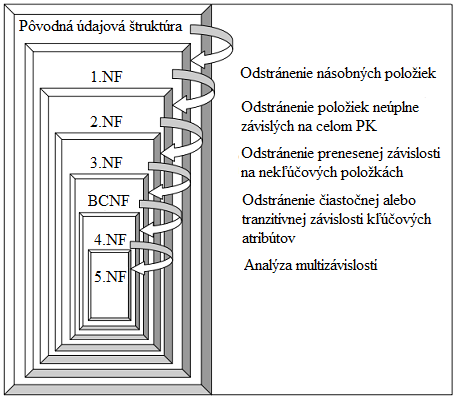
Obrázok 7. Postup normalizácie [16].

Obrázok 8. Návrh databázového systému.
Zhrnutie 3. kapitoly
Cieľom kvalitného návrhu je, že databáza musí uchovávať údaje potrebné na plnenie informačných požiadaviek známych v čase návrhu databázy, ale aj budúcich požiadaviek.
E‑R diagram – je grafický nástroj, ktorý sa používa pri návrhu databázových systémov na vyjadrenie modelu údajov. V rámci neho sú definované jednotlivé údajové objekty sveta (entity) a vzájomné vzťahy medzi nimi.
Entita – je údajový objekt, o ktorom chceme uchovávať údaje.
Atribúty entity – vyjadrujú jej bližšiu charakteristiku/vlastnosti.
Doména atribútu – je obor hodnôt, ktorý môže atribút nadobúdať.
Relácia – definuje vzťah, spojenie medzi jednotlivými entitami.
Primárny kľúč – jednoznačne identifikuje každú inštanciu (každý záznam) v entite.
Údajový model – je množina pravidiel, podľa ktorých sú organizované logické vzťahy medzi údajmi v databáze.
Typy údajových modelov:
- Hierarchický – je založený na hierarchickej (stromovej) štruktúre údajov. Jeho modelovanie zodpovedá vzťahom typu 1 : N a 1 : 1.
- Sieťový – je orientovaný graf, v ktorom sú entity zobrazené pomocou uzlov a vzťahy pomocou prepojovacích čiar. Môžeme modelovať vzťahy typu 1 : 1, 1 : N, M : N. Z dôvodu svojej implementačnej náročnosti a zložitosti bol používaný pomerne málo.
- Relačný – relácie sú reprezentované ako dvojrozmerné tabuľky. Každá tabuľka potom zastupuje konkrétnu entitu reálneho sveta. Modelujeme vzťahy typu 1 : 1, 1 : N, M : N.
Definícia relácie v relačnom údajovom modeli:
- Je reprezentovaná ako tabuľka (matica zostavená z M riadkov a N stĺpcov).
- Jeden riadok reprezentuje jeden záznam.
- Nemôžu byť dva rovnaké riadky, odlišujú sa minimálne v hodnote primárneho kľúča.
- Poradie jednotlivých riadkov je preto nepodstatné.
- Jeden stĺpec reprezentuje jeden atribút.
- Každý atribút (stĺpec) má jedinečný názov odlišný od ostatných atribútov.
- Poradie jednotlivých stĺpcov je preto nepodstatné.
- Každý atribút má svoju doménu, ktorá vyjadruje množinu dovolených hodnôt.
Objektový údajový model v DBS vychádza zo známych princípov objektovo orientovaného modelovania a programovania. Je však ďalej obohatený o techniky reprezentácie vzťahov, dopytovania, transakčného prístupu a podobne.
ODBMS priniesli oproti relačným databázam kvalitnejšie údajové a procedurálne modelovanie. Prejavuje sa predovšetkým nasledujúcimi charakteristikami:
- Spájanie príbuzných údajov.
- Spájanie údajov s funkciami.
- Spájanie databázového a programovacieho jazyka [17].
ORSRBD sa snažia využiť prednosti z relačných aj z objektových systémov. Je tu zachovaná jednoduchosť z relačného modelu a navyše získavajú výhody z objektového modelu.
Normalizácia je proces, pomocou ktorého rozkladáme relácie s cieľom jednoduchšej manipulácie s údajmi, zabránenia redundancie údajov a lepšej konzistencie. Celý proces prebieha aplikovaním jednotlivých pravidiel, ktoré nazývame normálové formy.
Úprava DB do prislúchajúcej normálnej formy umožňuje eliminovať jej anomálie. Odstránenie anomálií v databáze zabezpečí jej konzistentnosť, efektívnosť vyhľadávania, a tiež minimalizáciu redundancie údajov. Medzi základné anomálie databázy patria:
- anomália vkladania nových údajov,
- anomália aktualizácie údajov,
- anomália odstraňovania údajov.
Otázky na zopakovanie
- Čo je E‑R diagram a z akých prvkov sa skladá?
- Z akých prvkov sa skladá entitno‑relačný diagram?
- Charakterizujte údajový model.
- Aké typy údajových modelov poznáme?
- Opíšte jednotlivé údajové modely.
- Vymenujte a opíšte základné zložky relačného údajového modelu.
- Vymenujte hlavné dôvody na použitie objektových údajových modelov.
- Opíšte OO databázové systémy.
- Vymenujte a opíšte základné pojmy objektovo orientovaného modelu.
- Vysvetlite pojem objektovo‑relačné systémy.
- Vysvetlite, čo je úlohou normalizácie?
- Aké anomálie dokážeme správnou normalizáciou odstrániť? Uveďte príklady.
Doplňujúce materiály ku štúdiu
- Otte, Lukáš: Databázové systémy – Životní cyklus databáze. Ostrava : Vysoká škola Baňská, Technická univerzita Ostrava, Fakulta strojní, 2013. [Cit. 2020‑14‑05]. Dostupné na internete: ⟨
 http://projekty.fs.vsb.cz/463/edubase/VY_01_044/Datab%C3%A1zov%C3%A9%20syst%C3%A9my.pdf ⟩.
http://projekty.fs.vsb.cz/463/edubase/VY_01_044/Datab%C3%A1zov%C3%A9%20syst%C3%A9my.pdf ⟩. - Štrbo, Milan: Modelovanie databázových systémov. Trnava : Pedagogická fakulta Trnavskej univerzity v Trnave, 2020. ISBN 978‑80‑568‑0340‑0. [Cit. 2020‑04‑02]. Dostupné na internete: ⟨https://pdf.truni.sk/download?e‑ucebnice/strbo‑mdbs‑2020.pdf 271,00 B (271,00 B), 18. 6. 2020⟩.
- Relational Database Systems – An Introduction, Chapter 1, Microsoft SQL Server 2008 : A Beginner’s Guide. [Cit. 2020‑14‑05]. Dostupné na internete: ⟨http://www.mhprofessional.com/downloads/products/0071546383/0071546383_ch01.pdf ⟩.
- Szabó, Peter: Databázové a informačné systémy. Košice : Technická univerzita v Košiciach, 2005. [Cit. 2020‑14‑05]. Dostupné na internete: ⟨https:/spseke.sktutorprednasky/{dbs/rdm.html}⟩.
- Duračiová, Renata: Databázové systémy v GIS. Slovenská technická univerzita v Bratislave, 2014. ISBN 978‑80‑227‑4292‑4. [Cit. 2020‑14‑05]. Dostupné na internete: ⟨https://www.researchgate.net/profile/Renata_Duraciova/publication/317102680_Databazove_systemy_v_GIS/links/5926a0f5458515e3d457fa87/Databazove‑systemy‑v‑GIS.pdf ⟩.
- Fornusek, Ladislav: Databázové technológie v podnikových informačných systémoch. Olomouc : Moravská vysoká škola Olomouc, Ústav informatiky, 2009. [Cit. 2020‑14‑05]. Dostupné na internete: ⟨externdown:https:/theses.cz/{id5x5pamFornusekPIS2009-BP.pdf}⟩.
- Gorbár, Peter: Editor ER diagramů s podporou transformace do relačního modelu a SQL. Univerzita Karlova v Praze, Matematicko‑fyzikální fakulta, 2007, [Cit. 2020‑14‑05]. Dostupné na internete: ⟨https://www.ksi.mff.cuni.cz/~holubova/bp/Gorbar.pdf 1,67 MB (1,59 MiB), 6. 6. 2007⟩.
- Pribilová, Katarína: Databázové systémy 1. Trnava : Pedagogická fakulta Trnavskej univerzity v Trnave, 2013. ISBN 978‑80‑8082‑680‑2. [Cit. 2020‑14‑05]. Dostupné na internete: ⟨https://pdf.truni.sk/e‑ucebnice/databazove‑systemy1/ ⟩.
- Mišút, Martin – Juhásová, Lucia: Databázové systémy 2. Pedagogická fakulta Trnavskej univerzity v Trnave, 2014. ISBN 978‑80‑8082‑775‑5. [Cit. 2020‑14‑05]. Dostupné na internete: ⟨https://pdf.truni.sk/e‑ucebnice/databazove‑systemy2/ ⟩.
- Tekeľ, Gabriel: Výučbové nástroje pre relačné a objektové databázy. STU v Bratislave, Fakulta informatiky a informačných technológií, 2011. [Cit. 2020‑23‑05]. Dostupné na internete: ⟨https:/{is.stuba.skzpportalzp.pl?podrobnostizp=24158;lang=sk}⟩.
- Momjian, Bruce: PostgreSQL – Praktický průvodce. Computer Press, 2003. ISBN 80‑7226‑954‑2.
Normalizácia databáz: